
The math of risk equalization
June 27th, 2023
Piet Stam
Meet & greet
- What do you expect to learn from this course?
- My agenda
- First, an intro to the math
- Second, applying it to some data
- R package
rvedatabased on my PhD thesis
Context

- 🇳🇱 health care (basic benefits)
- 🇳🇱 health insurance
- 🇳🇱 system of risk equalization
- Traditional focus on incentives
- NOT actual behavior
- NOT effects (efficiency & equity)
Data collection
- Large national data set
- Population vs. sample
- Weights for insurance period
- Multiple records per insured
- Pseudonyms for merging data sets
Which are the “acceptable costs”?
“The costs of services that follow from a quality, intensity and price level of treatment that the sponsor considers to be acceptable to be subsidized.” (Van de Ven and Ellis, 2000)
Two extremes:
- Best practice costs
- Actual expenditures
Q: which is more health based?
🇳🇱: Y = actual expenditures with average prices for some services
Which subgroups to compensate?
“The REF equation should only include parameters which equalize cost differences in health status of an insured as a consequence of differences in age, gender and other objective measures of health status.” (Health Insurance Decree:389, p.23)
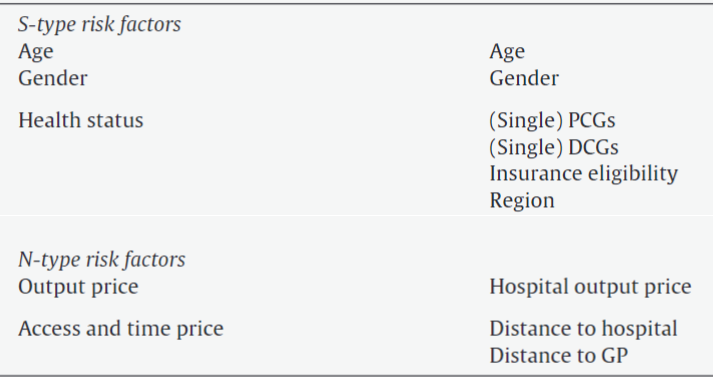
Compensation for S(olidarity)-type groups
- Age
- Gender
- Health status
No compensation for
N(on-solidarity)-type groups
- Propensity to consume
- Input prices
- Regional overcapacity (SID)
- Provider practice style
The regression equation
Y=f(S,N)+u=Sα+Nγ+u=L∑l=1Slαl+M∑m=1Nmγm+u
with
- Y health expenses observed during some period in time
- Sl is the lth S-type risk factor, l=1,...,L
- Nm is the mth N-type risk factor, m=1,...,M
- (u∼IID(0,1))
Which causal diagram?
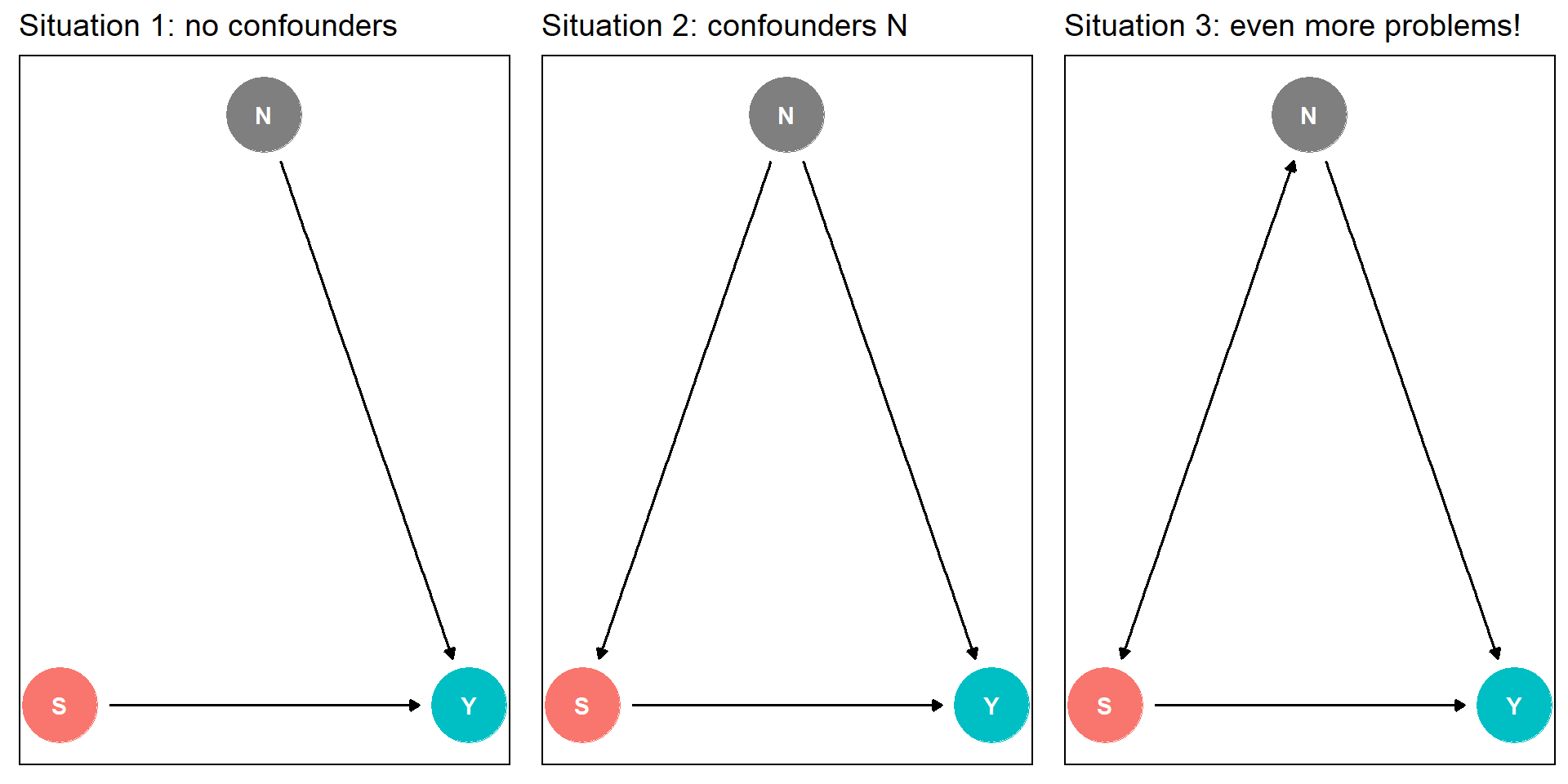
Big assumption
Define v:=Nγ+u and rewrite Y=Sα+Nγ+u⟺Y=Sα+v
⟹ˆα=(S′S)−1S′Y=(S′S)−1S′(Sα+v)=α+(S′S)−1S′Nγ+(S′S)−1S′u
⟹E[ˆα|S,N]=α⟺{S′N=0γ=0
What to do if assumption fails?
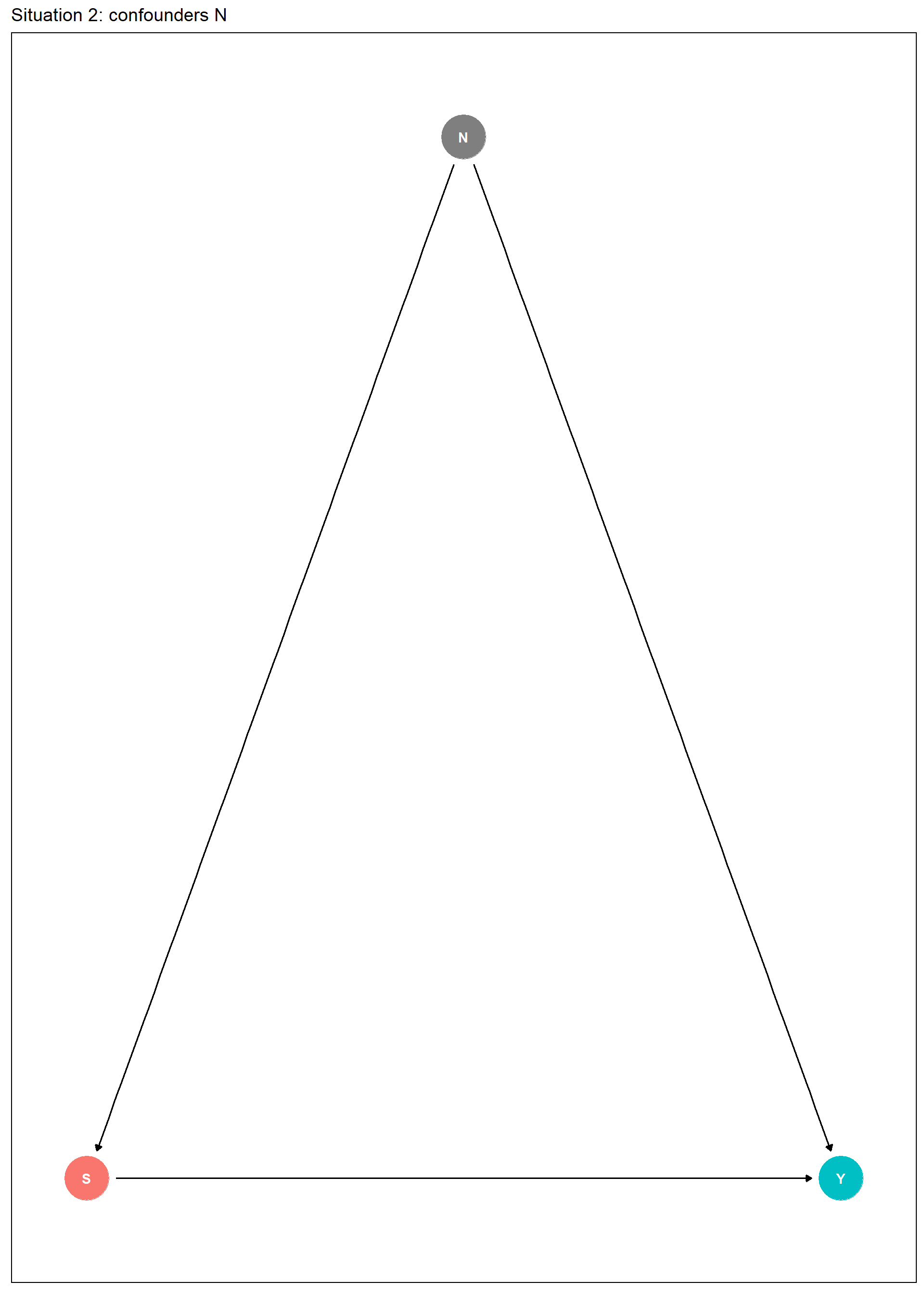
Schokkaert and Van de Voorde () recommend a 2-step method:
- estimate (α,γ) in regression with S and N variables
- predict Y with N set at prevalences
The formula then reads as follows:
ˆY=Sˆα+¯Nˆγ with ¯N being a row i/o matrix.
Or… ignore this omitted vars bias
In practice, we apply this equation:
Y=Xβ+ϵ
and try to extend X with as much (measurable) S-type variables as possible.
Regression without an intercept
Traditional OLS:
- include an intercept
- omit one category of age/gender
- omit one category of each other X (which one?)
OLS w/ risk equalization:
- do not include an intercept
- include all categories of all other X’s
- set total effect of age/gender := sum of Y
- set total effect of each other X := 0
Apply weights
- Weights W define length of insurance contract
- 0<W<=1
- Potential reasons for W<1:
- 2 or more records for 1 individual -> sum Y and X
- babies born
- people deceased
Use aggregation to save computer time
- “Vertical aggregation” for each unique combination of X
- Total number of rows = number of unique combinations
- W := sum of observations for each unique combination
- Y := average expenses ¯Y for each unique combination
- X := set of prevalences ¯X for each unique combination
- OLS estimation using these W, Y and X
- Bekijk mijn blog voor een eenvoudig voorbeeld
Region: individual & zip code data
- In 2002 a two-step approach was implemented:
- step 1: Y=Xβ+ϵ (indiv. level)
- step 2: ϵ=Z∗c+ξ (zip-code level)
- As ˆϵ=Y−ˆY step 2 can be read as:
- step 2: Y=1.ˆY+Z∗c+ξ
- Implicit restriction: ˆY and Z not correlated
- If this assumption is false, the estimators are inconsistent
- Therefore, ˆY was added to step 2 since the 2006 model
- Nowadays, one comprehensive regression at indiv. level
(Ex post) risk sharing
Definition: insurers are retrospectively reimbursed for some of the costs of some of their insurance members (Van de Ven and Ellis 2000)
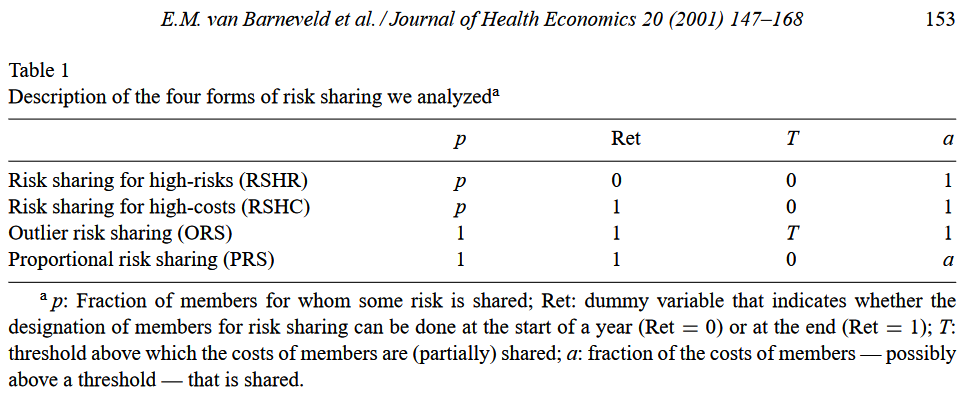
Assessment framework
Install package rvedata
Metadata
rvedata![]()
De inhoud van deze slides is beschikbaar onder de Creative Commons Naamsvermelding-GelijkDelen 4.0 Internationaal licentie.
De broncode voor het genereren van deze slides is beschikbaar op GitHub onder de MIT licentie.
Copyright (c) 2023 Piet Stam.
The math of risk equalization June 27th, 2023 Piet Stam